Daily Trend [10-20]
【1】MAGVIT: Masked Generative Video Transformer
【URL】http://arxiv.org/abs/2212.05199
【Time】2023-04-04
一、研究领域
视频生成、视觉分词器
二、研究动机
受到最近 DALL·E 等 generative image transformers 的成功的启发,希望通过利用 masked token modeling 和 multi-task learning 提出一种高效且有效的(多任务)视频生成模型。
三、方法与技术
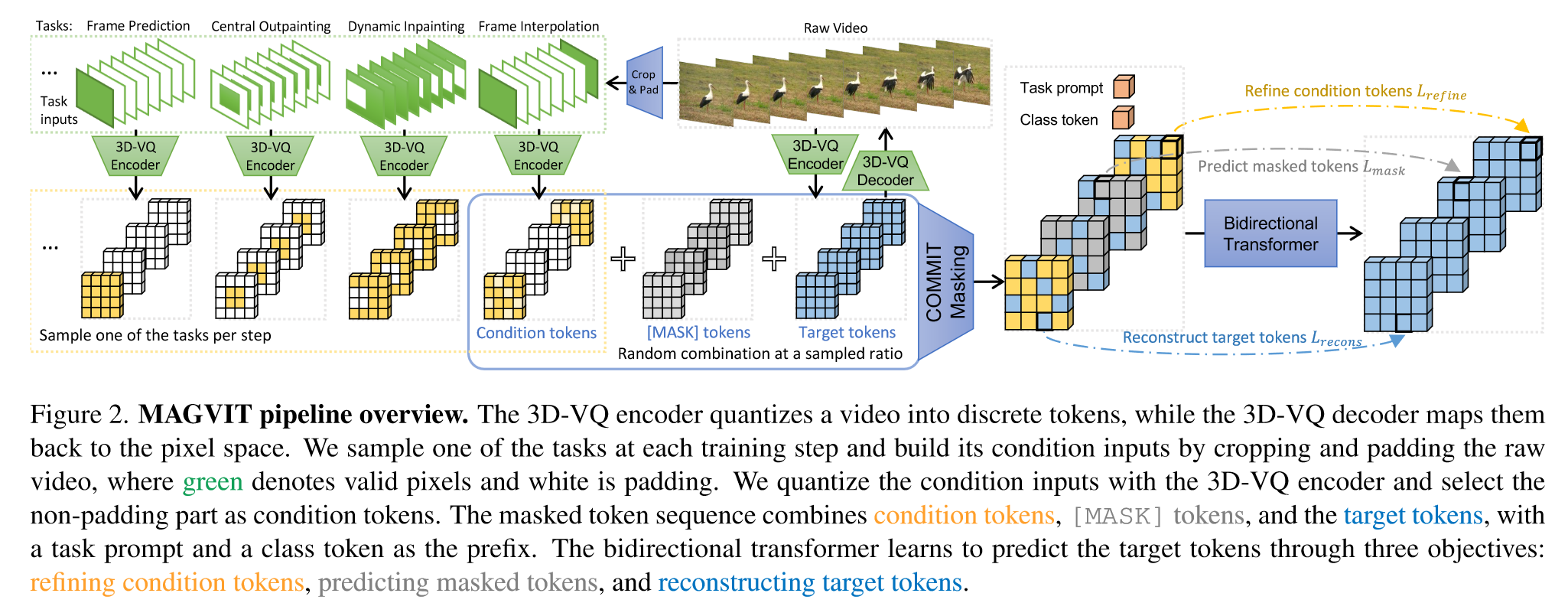
Base Model 是 non-autoregressive transformers;分两个阶段训练MAGVIT:
(1)Spatial-Temporal Tokenization:目的是将video离散化为tokens。基于 image VQGAN 构建 video VQ autoencoder,特别设计为3D-VQ架构,以对时间动态建模。初始化使用2D-VQ的权重,训练用的损失是逐帧的image perceptual loss。
(2)Multi-Task Masked Token Modeling:训练时,采用各种masking方案来促进不同条件下视频生成任务的学习。一共定义了10个任务。推理时,使用非自回归decoding method根据 K 个步骤的输入条件生成video tokens。
四、总结
有点好奇为什么一定要用non-autoregressive的架构。
五、推荐相关阅读
Language Model Beats Diffusion – Tokenizer is Key to Visual Generation
【2】DINOv2: Learning Robust Visual Features without Supervision
【URL】http://arxiv.org/abs/2304.07193
【Time】2023-04-14
一、研究领域
通用视觉特征,Data Selection (automatic pipeline)
二、研究动机
学习与任务无关的预训练表示已成为自然语言处理 (NLP) 的标准,作者希望探索:如果对大量 selected data 进行预训练,self-supervised learning 是否能够学习通用的视觉特征。
三、方法与技术
(1)Data Processing:过程直观如下
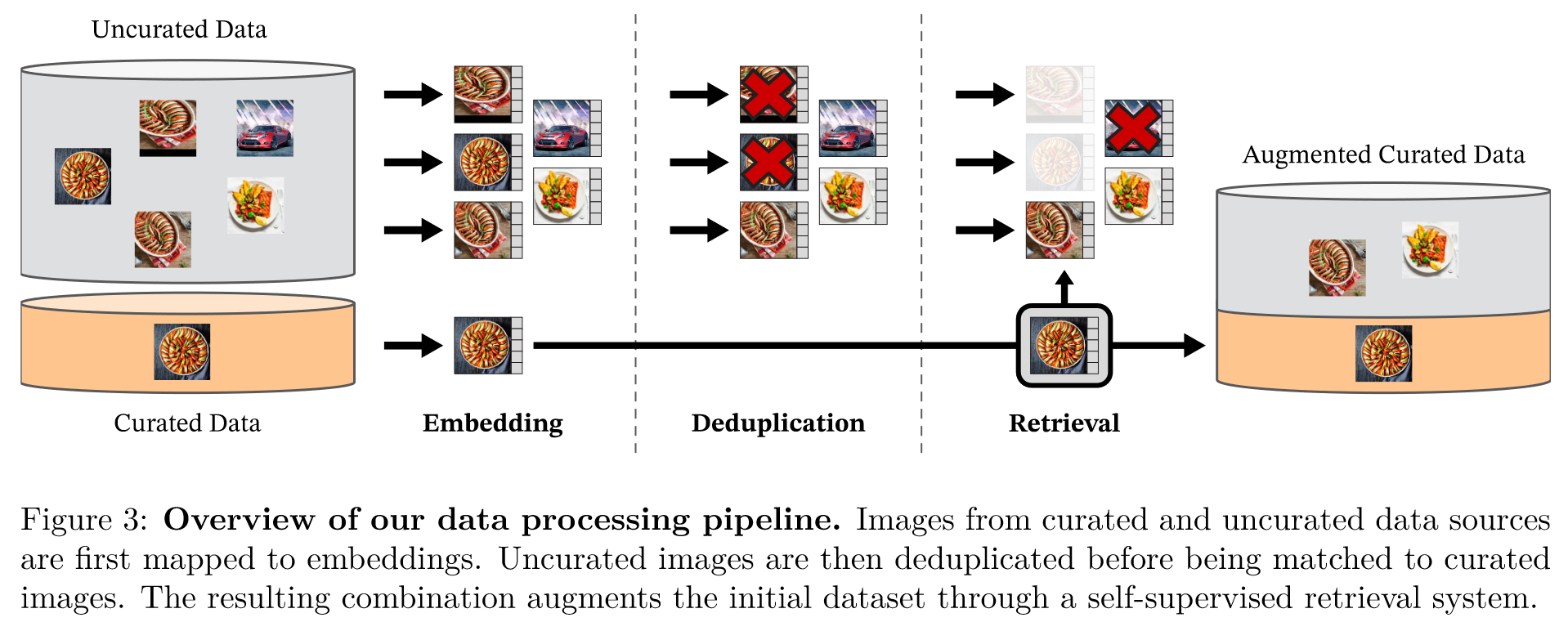
(2)Discriminative Self-supervised Pre-training:包括 Image-level objective,Patch-level objective,Untying head weights between both objectives,Sinkhorn-Knopp centering,KoLeo regularizer,Adapting the resolution
(3)Efficient implementation:一些加速和成本节约的实现
四、总结
DINOv2 是 一系列新的图像编码器,在没有监督的情况下对大量精选数据进行预训练。这是第一个针对图像数据的 SSL 工作,它产生的视觉特征可以缩小与(弱)监督替代方案在各种基准测试中的性能差距,并且无需进行微调。